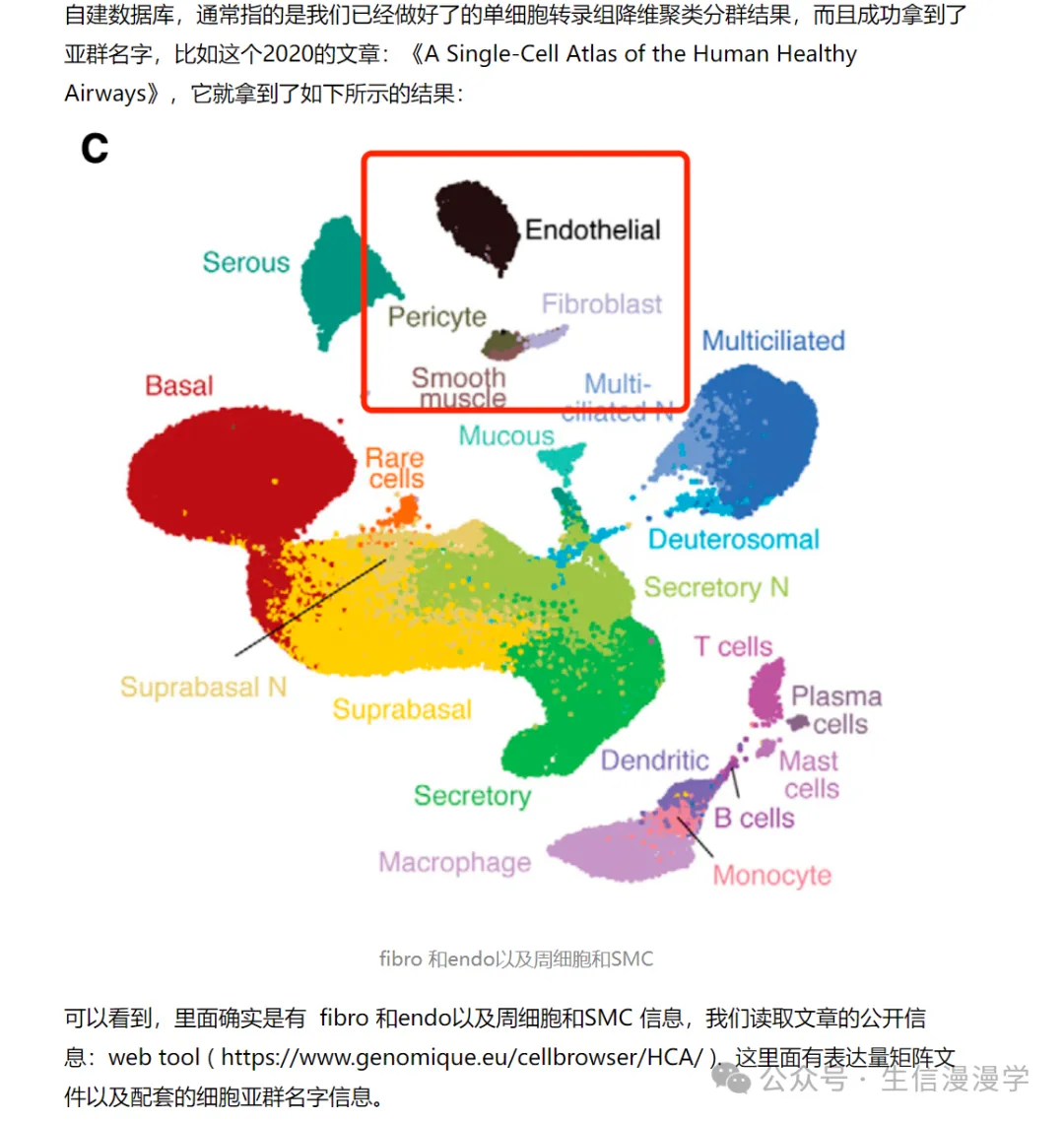
SingleR及数据库资源包celldex简介
- 2026-04-03 09:32:17
写在开头
上次在整理手动注释结合在线注释网站使用的时候有提到,之前准备学习一下singleR自动注释单细胞亚群的方法,但一直拖拖拖,就拖到了4月底
不过好歹算是开始学习了,顺便整理了里面提到的文献:人海绵体单细胞转录组图谱
学习推文来源:使用singleR基于自建数据库来自动化注释单细胞转录组亚群,里面有提供V5版本的全部代码以及完整的分析流程,我主要是整理记录下自己复现的分析过程!

学习视频参考:人工注释与singleR注释差异(视频好像没办法插入链接,大家有需要的话,自己去技能树的视频号找一下直播回放)
那首先我们来了解一下SingleR包叭!
SingleR简介
SingleR——基于参考的单细胞RNA-Seq注释
SingleR 是一种用于单细胞 RNA 测序 (scRNAseq) 数据的自动注释方法。给定具有已知标签的样本(单细胞或块)的参考数据集,它根据与参考的相似性标记测试数据集中的新细胞。
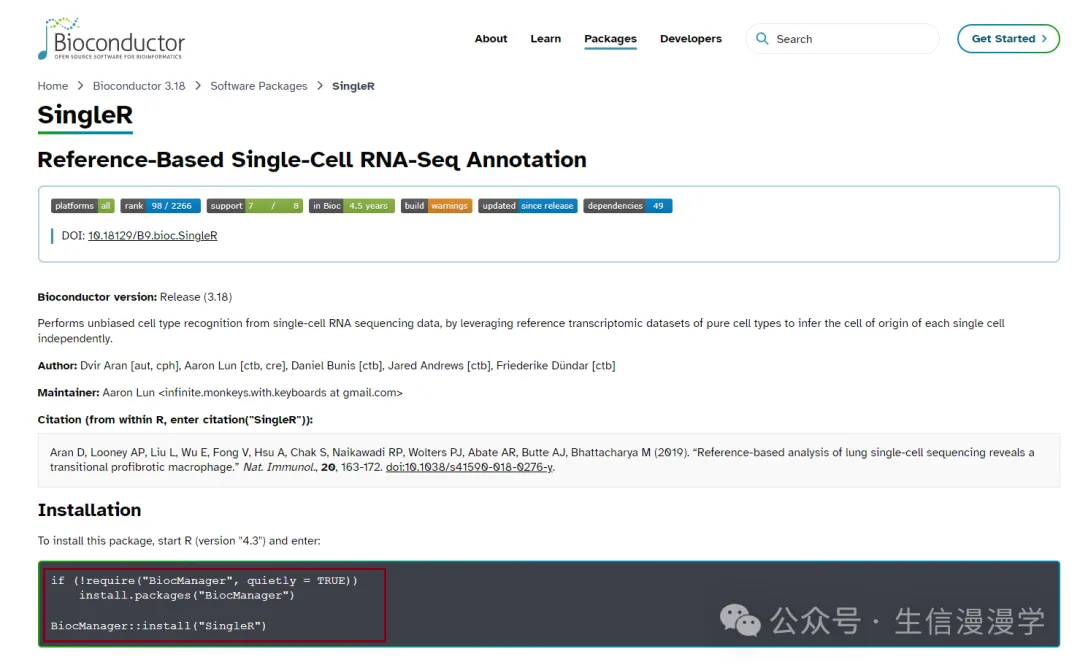
使用BiocManager::install("SingleR")安装即可!
具体的使用方法可以参考Bioconductor提供的使用手册:
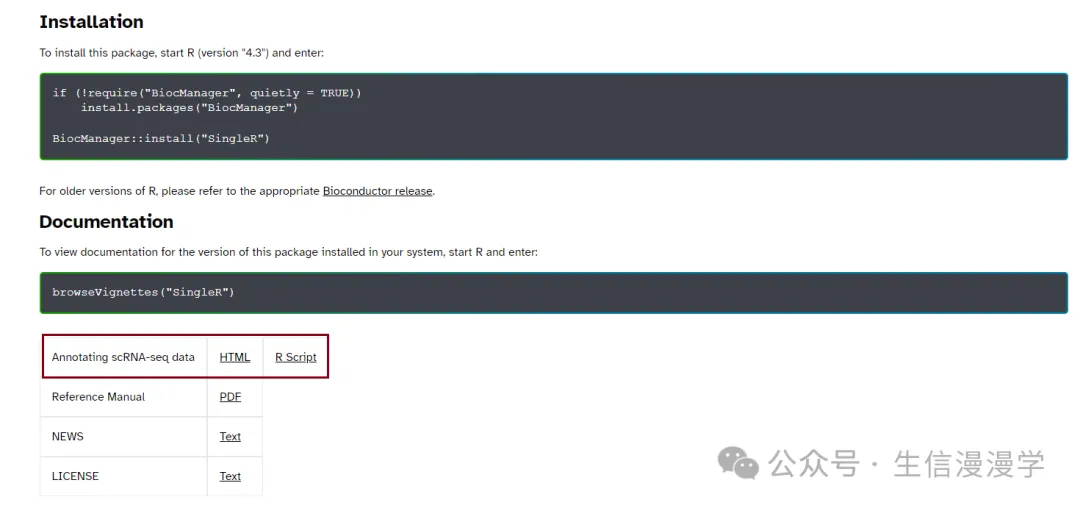
Using SingleR to annotate single-cell RNA-seq data
https://bioconductor.org/packages/release/bioc/vignettes/SingleR/inst/doc/SingleR.html

singleR优点
对于参考数据集,手动解释簇和定义标记基因只需要完成一次,并且这种生物学知识可以自动传播到新的数据集中
可以不需要提前降维聚类分群,直接针对表达量矩阵本身,就可以给每个细胞一个身份,这样的话它就跳过了降维聚类分群过程引入的误差。
singleR使用步骤:
需要一个数据库文件,构建SingleR进行单细胞亚群命名的参考数据库
使用SingleR包里面的SingleR函数即可把数据库里面的细胞亚群注释信息映射到需要命名的单细胞转录组数据集里面。
成功的运行了SingleR包里面的SingleR函数之后,就可以拿到每个单细胞的具体的身份信息

使用 SingleR 的最简单方法是根据内置数据集对单元格进行批注,celldex 软件包通过专用检索功能提供对多个参考数据集(主要来自批量 RNA-seq 或微阵列数据)的访问
singleR官方数据库资源包celldex
singleR将官方数据库资源做成了一个celldex包,目前已经上传到Bioconductor,可以使用BiocManager::install("celldex")安装
可以查看一下具体有哪些数据库:
Cell type references
https://bioconductor.org/packages/release/data/experiment/vignettes/celldex/inst/doc/userguide.html
7个数据库:
Human primary cell atlas (HPCA)
HPCA包括来自人类原代细胞的公开可用的微阵列数据集(Mabbott等人,2013),还包含许多经过处理或从致病条件下收集的细胞和细胞系。
大多数标签涉及血液亚群,但也提供来自其他组织的细胞类型。
Blueprint/ENCODE
包括 Blueprint (Martens and Stunnenberg 2013) 和 ENCODE 项目 (The ENCODE Project Consortium 2012) 生成的纯基质和免疫细胞的大量 RNA-seq 数据。
适合不需要精细分辨率的混合样品,特别适用于需要快速易于解释的标记的情况。它提供了不错的免疫细胞颗粒度,但是不包含更精细的单核细胞和树突状细胞亚型。
Mouse RNA-seq
包括从基因表达综合下载的小鼠批量RNA-seq数据集的集合(Benayoun等人,2019)。有多种细胞类型可供选择,同样主要来自血液,但也覆盖其他几种组织。
适合低分辨率标记的脑、血液或心脏的散装组织样本
Immunological Genome Project (ImmGen)
ImmGen参考包括来自同名项目的纯小鼠免疫细胞的微阵列图谱(Heng等人,2008)。这是目前分辨率最高的免疫参考 - 考虑到精细标记的粒度
Database of Immune Cell Expression/eQTLs/Epigenomics (DICE)
DICE参考包括来自同名项目的分选细胞群的批量RNA-seq样本(Schmiedel等人,2018)。
适用于 CD4 + T 细胞亚群,尽管在某些情况下缺乏 CD4 + 中央记忆和效应记忆样本可能会降低准确性。此外,树突状细胞和单个 B 细胞亚群的缺乏可能导致这些群体在典型的 PBMC 样本中被不正确地标记或修剪其标记。
Novershtern hematopoietic data
来自GSE24759的分类造血细胞群的微阵列数据集组成(Novershtern 等人,2011 年)。
为人类免疫参考文献中的髓系和祖细胞提供了最大的分辨率,与其他免疫参考相比,它的 T 细胞亚群更少,但含有更多的 NK、红细胞和粒细胞亚群。它可能是骨髓样本的最佳选择。
Monaco immune data
包括来自GSE107011的分类免疫细胞群的批量RNA-seq样品(Monaco等人,2019)。
是最能涵盖典型PBMC样品所有碱基的人体免疫参考,提供广泛的 B 细胞和 T 细胞亚群,区分经典和非经典单核细胞,包括基本的树突状细胞亚群,还包括中性粒细胞和嗜碱性粒细胞样本,以帮助识别可能已滑入 PBMC 制剂的小型污染群体。
基于提供的数据库构建ref:
ref <- HumanPrimaryCellAtlasData()
ref <- BlueprintEncodeData()
ref <- MouseRNAseqData()
ref <- ImmGenData()
ref <- DatabaseImmuneCellExpressionData()
ref <- NovershternHematopoieticData()
ref <- MonacoImmuneData()
正经结尾
因为SingleR官方数据库资源包celldex里面提供的7大数据库资源不一定适合我们需要的数据集,所以我们可以通过找到一个需要的参考数据集,然后自行构建SingleR的数据库。
那下期推文就一起来试试看自建一个数据库叭!今天就先浅浅了解一下SingleR包以及celldex数据库资源包