大家好,我是小涵~
身为开发者或测试同学,你一定想过:要是能把公司那些厚厚的 PRD、技术文档、历史用例 全喂给 AI,让它变成一个“随叫随到”的业务专家,那该多爽?
但理想很丰满,现实很骨感。直接把数据传给 ChatGPT?合规红线分分钟让你卷铺盖走人;大模型胡说八道?业务逻辑幻觉能把你坑惨。
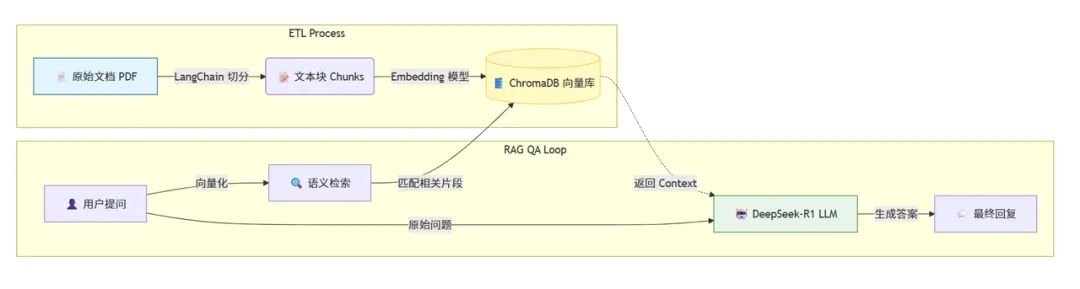
今天,咱们就聊透如何利用 RAG(检索增强生成) 技术,基于 Python 全栈生态,在本地搭建一套既安全又精准的企业级私有知识库,建议点赞收藏。
为什么直接问大模型不行?因为它没读过你公司的私密文档。
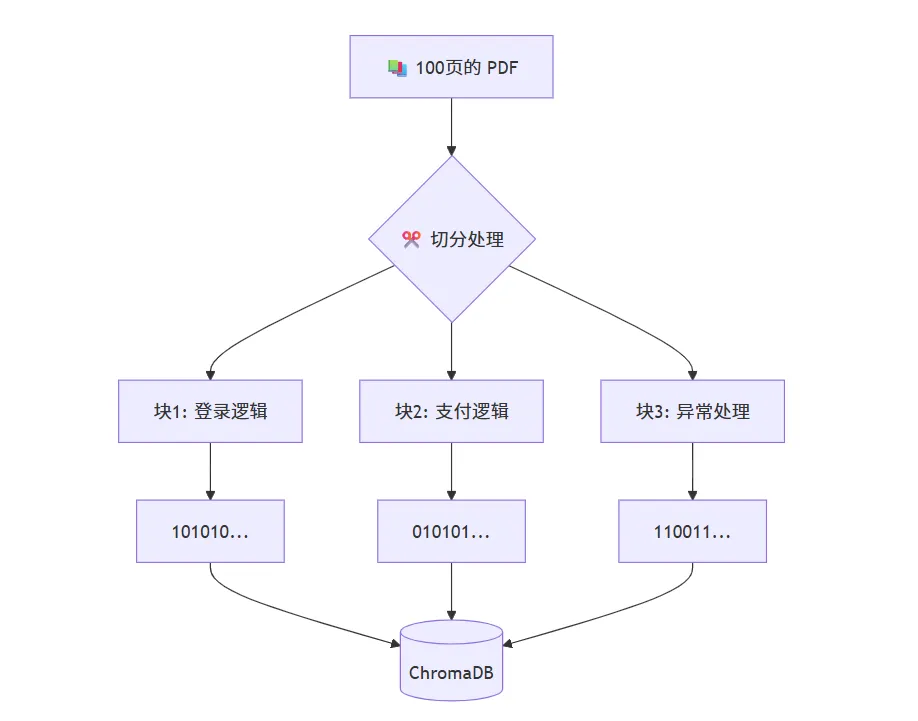
RAG 技术的逻辑就像是给 AI 安排了一场“开卷考试”:
翻书(检索):用户提问时,系统先去本地文档里抓取最相关的片段。
打小抄(增强):把这些片段和问题一起打包发给 AI。
作答(生成):AI 根据“小抄”里的事实内容,给出有据可依的回答。
全程数据不出本地,彻底告别泄密风险!
想要快速跑通一套 RAG 系统,咱们得选好这几件“趁手兵器”:
Ollama:目前最简单的本地大模型运行工具,一行命令启动 DeepSeek。
DeepSeek-R1:国产之光!7B 版本在普通电脑上就能跑,逻辑推理能力极其硬核。
LangChain:AI 开发界的“Spring Boot”,把复杂的调用链条全部封装好了。
ChromaDB:轻量级向量数据库,无需安装 Docker,数据直接存在本地文件夹。
本教程基于 Windows 10/11 或 macOS 系统,要求 Python 3.10+。即使你是编程小白,跟着以下步骤也能跑通。
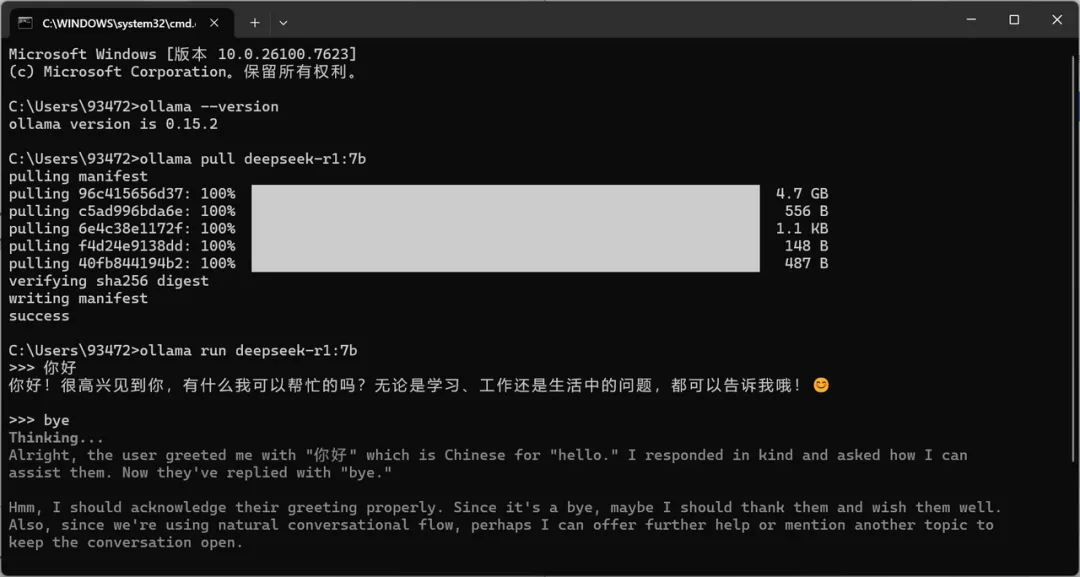
步骤一:安装 Ollama (本地大模型底座)
Ollama 是目前最流行的本地 LLM 运行工具,它把复杂的模型配置封装成了类似 Docker 的简单命令。
下载安装包:
验证安装:
拉取 DeepSeek 模型:
ollama pull deepseek-r1:7b
小贴士: 如果下载速度极慢,可以尝试更换网络环境,或者使用手机热点先下载一小会儿再切回 WiFi。
测试运行:
步骤二:搭建 Python 开发环境
为了避免污染你电脑上现有的 Python 环境,我们强烈建议使用虚拟环境 (Virtual Environment)。
创建项目文件夹
在桌面或任意磁盘创建一个新文件夹,命名为 local_rag,并在 VS Code 中打开它。
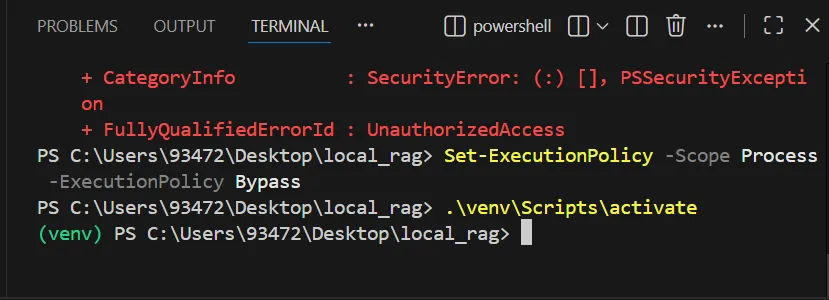
创建虚拟环境
在 VS Code 的终端(Terminal)中,根据你的系统执行以下命令:
# 创建名为 venv 的虚拟环境 python -m venv venv # 激活环境 (注意反斜杠) venv\Scripts\activate
# 创建名为 venv 的虚拟环境 python3 -m venv venv # 激活环境 source venv/bin/activate
配置国内镜像源 (加速下载)
默认的 pip 源在国外,下载速度很慢且容易超时。建议临时配置清华源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
安装核心依赖库
复制以下命令并在终端执行(这是全栈开发的核心库):
pip install langchain langchain-community langchain-core chromadb ollama pypdf
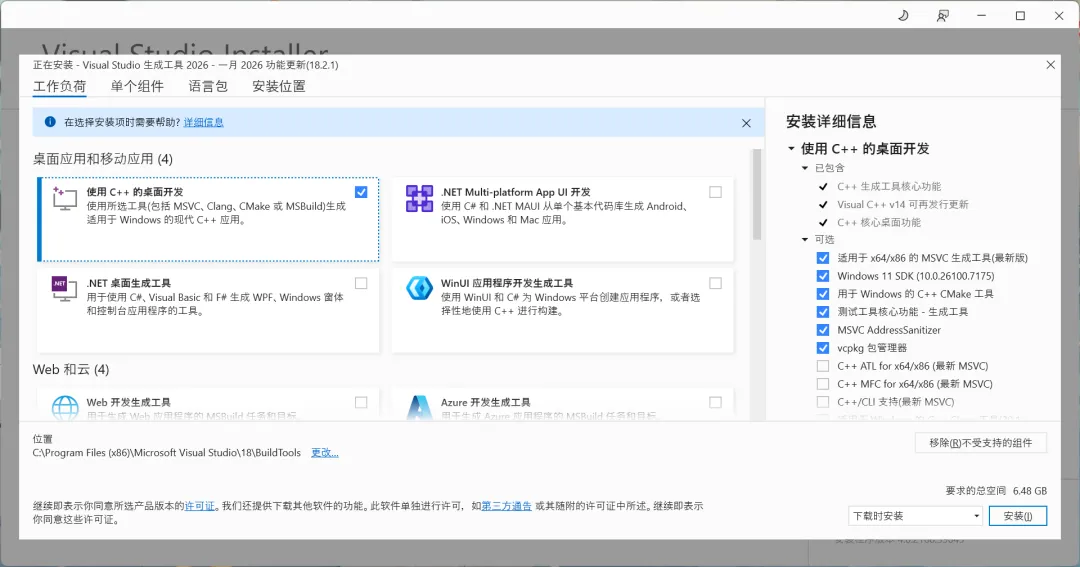
⚠️ Windows 用户必看:C++ 编译报错解决
如果安装过程中出现红色报错:error: Microsoft Visual C++ 14.0 or greater is required。
原因: ChromaDB 依赖 C++ 编译环境,而你的电脑没有安装。
解决:
下载 Microsoft C++ Build Tools (微软官方工具)。
安装时勾选左上角的 “使用 C++ 的桌面开发”。
安装完成后重启电脑,再次运行 pip install ... 即可成功。
步骤三:准备测试数据
在项目根目录下,创建一个名为 documents 的文件夹。
找一个你熟悉的 PDF 文档(比如《员工手册.pdf》或《产品需求文档.pdf》),放入该文件夹。
注意: 尽量使用纯文本生成的 PDF,避免使用扫描件(全是图片的 PDF),否则需要额外安装 OCR 库。
至此,环境搭建全部完成!你的目录结构应该长这样:
local_rag/ ├── venv/ # 虚拟环境文件夹 (自动生成) ├── documents/ # 存放你的 PDF │ └── test.pdf └── (等待创建 app.py)
在这一步,我们将编写 Python 代码,打通“文档读取 -> 向量化 -> AI 回答”的全流程。为了方便管理,我们将代码写在一个名为 app.py 的文件中。
准备工作:创建文件
创建 Python 文件:
在 VS Code 左侧的文件列表中,右键点击空白处 -> New File (新建文件) -> 命名为 app.py。
准备测试文档:
确保你的 documents 文件夹里已经放入了一个 PDF 文件(例如 test.pdf)。如果没有,随便找一个不涉密的 PDF 放进去。
第一步:导入工具包
打开 app.py,将以下代码复制进去。这些是我们刚才安装的“全栈武器库”。
import os # 导入 LangChain 的核心模块 from langchain_community.document_loaders import PyPDFLoader, DirectoryLoader # 用于加载 PDF from langchain.text_splitter import RecursiveCharacterTextSplitter # 用于切分文本 from langchain_community.embeddings import OllamaEmbeddings # 用于将文本转为向量 from langchain_community.vectorstores import Chroma # 向量数据库 from langchain.chains import RetrievalQA # 检索问答链 from langchain_community.llms import Ollama # 大模型接口 # 全局配置参数 MODEL_NAME = "deepseek-r1:7b" # 对应你在 Ollama 里下载的模型名 DOC_PATH = "./documents" # 文档存放路径 DB_PATH = "./vector_db" # 向量数据库保存路径 print("✅ 依赖导入成功!环境配置正常。")
第二步:编写 ETL 流程 (Extract-Transform-Load)
在 app.py 中继续追加以下代码。这部分负责把“人看的 PDF”变成“机器看的向量”。
def create_vector_db(): """ 函数功能:构建向量数据库 1. 读取 PDF 2. 切分文本 3. 向量化并存储 """ print(f"🔄 正在加载 {DOC_PATH} 下的文档...") # 1. 加载文档# 使用 DirectoryLoader 扫描目录下所有的 .pdf 文件 loader = DirectoryLoader(DOC_PATH, glob="*.pdf", loader_cls=PyPDFLoader) documents = loader.load() # 如果没找到文档,报错提示if not documents: print(f"⚠️ 错误:在 {DOC_PATH} 下未找到任何 PDF 文件!") return None print(f"📄 已加载文档数:{len(documents)} 页") # 2. 切分文档 (Chunking)# 为什么要切分?因为大模型一次吃不下整本书,需要切成小块。# chunk_size=500: 每块约 500 个字符# chunk_overlap=50: 每块之间重叠 50 个字符,防止句子被切断 text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = text_splitter.split_documents(documents) print(f"✂️ 文档已切分为 {len(chunks)} 个数据块") # 3. 向量化并存储 (Embedding) print("🔄 正在构建向量数据库 (这步需要一点时间)...") # 使用 Ollama 提供的本地 Embedding 模型,数据不出本地 embeddings = OllamaEmbeddings(model=MODEL_NAME) # 将切分好的 chunks 转换成向量,并存入 ChromaDB vectordb = Chroma.from_documents( documents=chunks, embedding=embeddings, persist_directory=DB_PATH ) # 持久化到磁盘,下次不用重新构建 print(f"✅ 向量数据库已构建完成!保存在:{DB_PATH}") return vectordb
第三步:编写问答交互逻辑 (QA Chain)
继续追加代码。这部分负责接收你的问题,去数据库查资料,然后让 AI 回答。
def ask_ai(): """ 函数功能:启动问答助手 """ print("🤖 AI 助手正在初始化...") # 1. 加载现有的向量数据库 embeddings = OllamaEmbeddings(model=MODEL_NAME) vectordb = Chroma(persist_directory=DB_PATH, embedding_function=embeddings) # 2. 初始化本地大模型 DeepSeek# temperature=0.1 表示让 AI 回答严谨一点,不要瞎编 llm = Ollama(model=MODEL_NAME, temperature=0.1) # 3. 构建“检索问答链”# k=3 表示每次去数据库找 3 段最相关的资料给 AI 参考 qa_chain = RetrievalQA.from_chain_type( llm=llm, retriever=vectordb.as_retriever(search_kwargs={"k": 3}), return_source_documents=True # 让 AI 告诉我们答案出自哪里 ) # 4. 进入问答循环while True: query = input("\n🙋 请输入问题 (输入 exit 退出): ") if query == "exit": print("👋 再见!") break print("🤔 DeepSeek 正在思考...") # 调用 AI 进行回答 result = qa_chain.invoke({"query": query}) # 打印结果 print("\n💡 AI 回答:") print(result['result']) print("\n📚 参考文档:") for doc in result['source_documents']: # 打印出参考了哪个文件的第几页 print(f"- {os.path.basename(doc.metadata['source'])} (第 {doc.metadata['page']+1} 页)")# 程序入口if __name__ == "__main__": # 如果是第一次运行,或者添加了新文档,请取消下面这行代码的注释: # create_vector_db() # 启动问答 ask_ai()
如何运行代码?
首次运行(构建库):
找到代码最后的 if __name__ == "__main__": 部分。
去掉 create_vector_db() 前面的 # 号(取消注释)。
在终端输入:python app.py
现象: 你会看到进度条,等待数据库构建完成。
后续运行(直接问答):
构建过一次后,可以把 create_vector_db() 前面再加回 # 号。
再次运行 python app.py,直接进入提问模式。
在实际开发中,你可能会遇到这些“坑”:
运行速度慢:如果是纯 CPU 推理,建议换用 deepseek-r1:1.5b 这种小尺寸模型。
AI 瞎编:将模型的 temperature(随机性)设置为 0.1,让 AI 变严谨,不确定的别乱说。
PDF 解析失败:尽量使用文字版 PDF。如果是图片扫描件,得额外接入 OCR 模块。
恭喜你!到这里你已经跑通了一个本地 Demo。
但这只是冰山一角。要真正达到“企业级可用”,你还需要掌握:
后端服务化:用 FastAPI 把 Python 脚本封装成高性能 API。
前端交互:开发支持“打字机流式输出”的 Web 界面。
复杂数据处理:如何处理 Excel 表格、PPT 甚至是数据库里的结构化数据。
如果你不想只做一个“代码搬运工”,而是想从零构建一套完整的 AI 应用体系,成为高薪的 AI 全栈开发工程师,那么接下来的内容你绝不能错过!
强力推荐:AI 全栈开发工程师实战课程
这篇文章只是 AI 开发世界的敲门砖。在我们的《AI 全栈开发工程师实战课程》中,我们将带你从 Python 基础一路杀到商业级 AI 项目落地:

为了帮大家快速从 Python 脚本跨越到 AI 全栈架构,我们准备了价值 1999 元的 AI 进阶资源包。
扫码添加企业微信,即可免费领取:
1️⃣ Python 基础全套课程:从零开始,扫清编程障碍。
2️⃣ 《AI 全栈开发工程师实战课程》一周试听:直击企业级 RAG 与 Agent 开发核心。
3️⃣ 资深导师 1v1 职业诊断:大厂专家为你梳理 AI 转型的避坑指南与简历亮点。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
